Publications
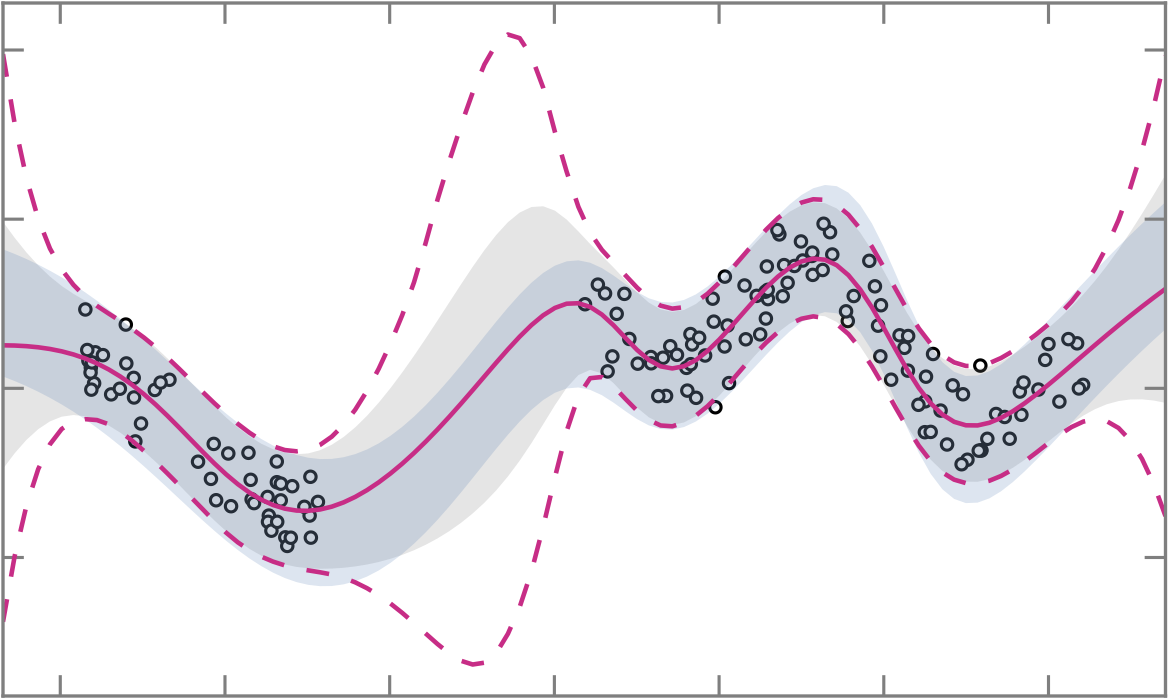
Approximating Full Conformal Prediction for Neural Network Regression with Gauss-Newton Influence
13th International Conference on Learning Representations (ICLR), 2025
paper (opens new window) / code (opens new window) / poster / slides
In this work, we construct prediction intervals for neural network regressors post-hoc without held-out data. This is achieved by approximating the full conformal prediction method (full-CP). Whilst full-CP nominally requires retraining the model for every test point and candidate label, we propose to train just once and locally perturb model parameters using Gauss-Newton influence to approximate the effect of retraining. On standard regression benchmarks and bounding box localization, we show the resulting prediction intervals are locally-adaptive and often tighter than those of split-CP.
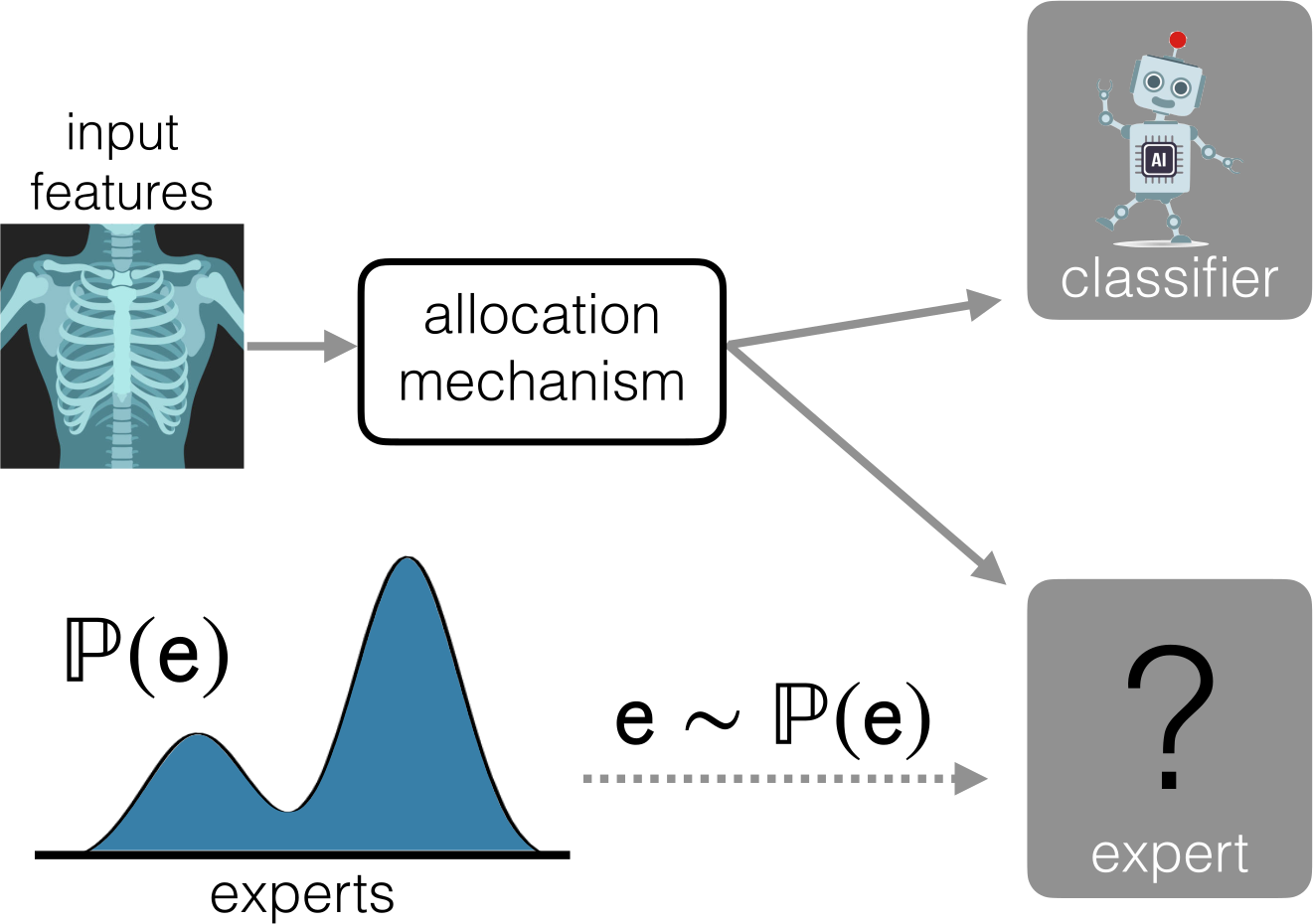
Learning to Defer to a Population: A Meta-Learning Approach
27th International Conference on Artificial Intelligence and Statistics (AISTATS), 2024
Oral presentation & Outstanding Student Paper award (top-1% of accepted papers)
paper (opens new window) / arXiv (opens new window) / code (opens new window) / poster / slides
We formulate a learning to defer (L2D) system that can cope with never-before-seen experts at test-time. We accomplish this by using meta-learning, considering both optimization- and model-based variants. Given a small context set to characterize the currently available expert, our framework can quickly adapt its deferral policy. For the model-based approach, we employ an attention mechanism that is able to look for points in the context set that are similar to a given test point, leading to an even more precise assessment of the expert’s abilities.
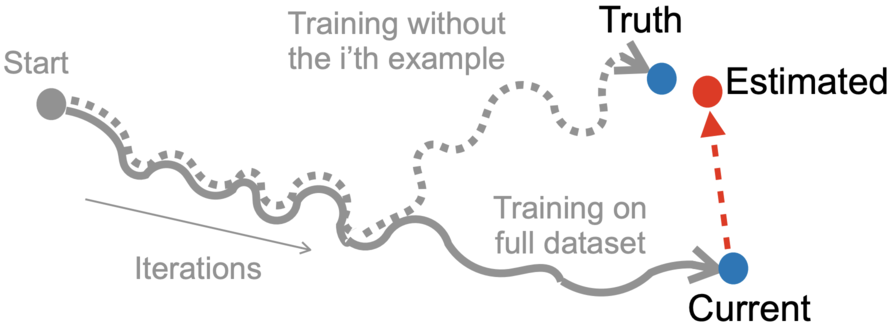
The Memory-Perturbation Equation: Understanding Model's Sensitivity to Data
37th Conference on Neural Information Processing Systems (NeurIPS), 2023
ICML 2023 Workshop on Principles of Duality for Modern Machine Learning
paper (opens new window) / arXiv (opens new window) / code (opens new window) / poster (opens new window)
We present the Memory-Perturbation Equation (MPE) which relates model’s sensitivity to perturbation in its training data. Derived using Bayesian principles, the MPE unifies existing sensitivity measures, generalizes them to a wide-variety of models and algorithms, and unravels useful properties regarding sensitivities. Our empirical results show that sensitivity estimates obtained during training can be used to faithfully predict generalization on unseen test data.
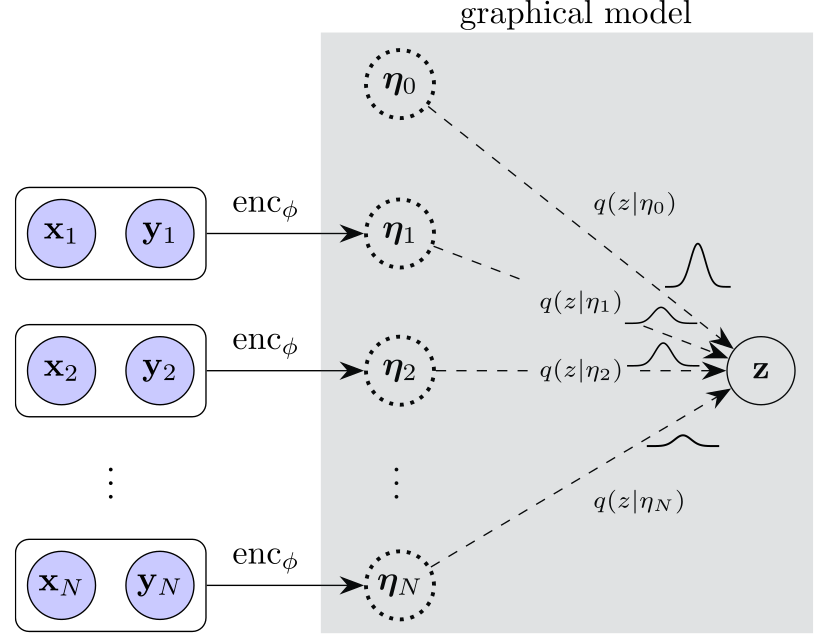
Exploiting Inferential Structure in Neural Processes
39th Conference on Uncertainty in Artificial Intelligence (UAI), 2023
5th Workshop on Tractable Probabilistic Modeling at UAI 2022
paper (opens new window) / arXiv (opens new window) / poster
This work provides a framework that allows the latent variable of Neural Processes to be given a rich prior defined by a graphical model. These distributional assumptions directly translate into an appropriate aggregation strategy for the context set. We describe a message-passing procedure that still allows for end-to-end optimization with stochastic gradients. We demonstrate the generality of our framework by using mixture and Student-t assumptions that yield improvements in function modelling and test-time robustness.
Publications (Pre-PhD)
These are papers published pre-PhD at the European Space Agency and University of Edinburgh.
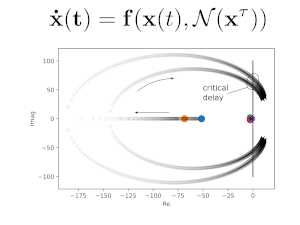
On the Stability Analysis of Deep Neural Network Representations of an Optimal State-Feedback
IEEE Transactions on Aerospace and Electronic Systems, 2020
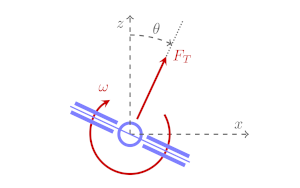
Learning the Optimal State-Feedback via Supervised Imitation Learning
Astrodynamics (Springer), 2019
paper (opens new window) / arXiv (opens new window) / code (opens new window)
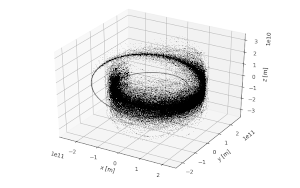
Machine Learning and Evolutionary Techniques in Interplanetary Trajectory Design
Modeling and Optimization in Space Engineering (Springer), 2019
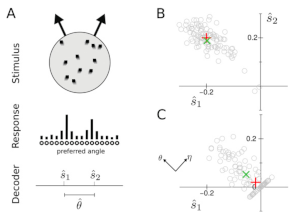
Unconscious Biases in Neural Populations Coding Multiple Stimuli
Neural Computation, 2018